人肉搜索引擎建模与仿真分析(CSharp语言)(精品)☆(包含选题审批表,任务书,开题报告,中期检查表,外文翻译,毕业论文30000字,实习报告,程序代码)
毕业设计(论文)中文摘要
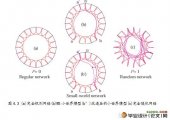
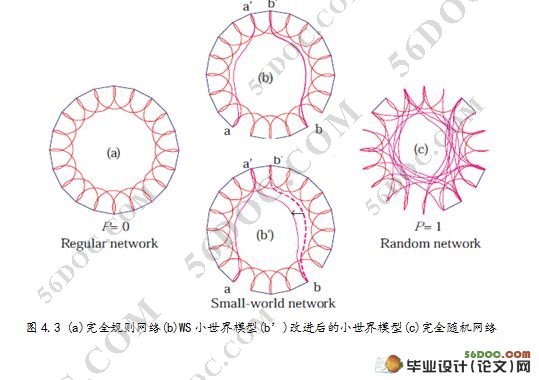
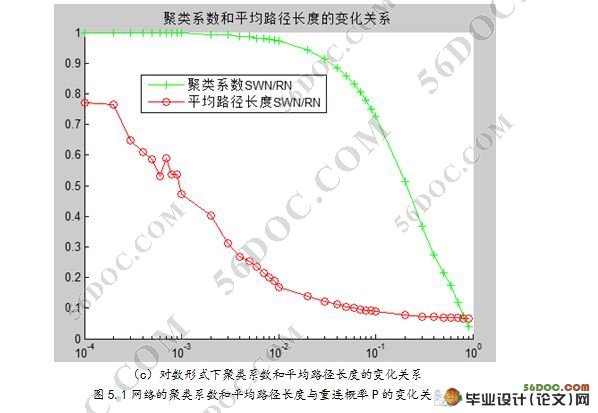
摘 要:本课题研究的是人肉搜索引擎建模与仿真分析,通过复杂网络中的小世界模型模拟人肉搜索现象。小世界网络模型是Watts和Strogatz在1998年提出的基于人类社会网络的网络模型(WS模型),通过调节一个参数可以使网络从规则网络向随机网络过渡。小世界网络中有2个特征性质:簇系数和平均路径长度。簇系数衡量的是网络的集团化程度;平均路径长度指网络中所有节点对之间的平均最短距离。如果一个网络同时具有较小的平均路径长度和较大的簇系数,则称该网络具有“小世界效应”(Small-world Effect)。在本篇论文中,我们在WS小世界模型的基础上进行了进一步的改进,增加了一个顶点集半径,用改进后的小世界模型来研究人肉搜索现象。并对仿真结果进行对比分析,通过图表,图形等显示出被仿真对象的各种状态,使模拟仿真的输出信息更加丰富。仿真结果表示我们的改进模型能够更好的描述人肉搜索引擎。
关键词:人肉搜索引擎,复杂网络,聚类系数,平均路径长度,建模与仿真
毕业设计(论文)外文摘要
Modeling and analysis on human flesh search engine
Abstract: This research includes the human flesh search engine modeling and simulation analysis. Human flesh search engine is simulated by small-world network, one of complex networks. The small-world network model is a network model (WS model) proposed by Watts and Strogatz in 1998 based on the human social networks, The state of small-world network can be get from the rules to the random network by adjusting parameters. Small-world network has two characteristics: Clustering coefficient and Average path length. Clustering coefficient is a measure of the group level of the network. The average path length refers to the average shortest distance between all nodes of network. If a network has both a smaller average path length and larger clustering coefficient, we say the network has "small-world” effect. In this paper, we increase the vertex set radius to improve the WS small-world model, and use the improved small-world model to study the phenomenon of human flesh search engine. Finally, we also analysis the simulation results and present them by charts and graphics. The simulation results show that our improved model has a better performance on simulation and modeling for human flesh search engine.
Keywords: Human flesh search engine, Complex network, Clustering coefficient, Average path length, Modeling and simulation
(1)本课题的研究手段是运用模拟仿真技术:
1.建立模型
模拟仿真是一基于模型的活动,是用模型模拟来代替真实系统进行实验和研究。因此,首先就要对待仿真的问题进行定量描述,这就是建立系统的数学模型。模型是对真实世界的模仿,真实世界是五彩缤纷的,因此模型也是千姿百态的;根据模型中是否包含随机因素,可分为随机型和确定型模型。根据模型是否具有时变性,可分为动态模型和静态模型;根据模型参数是否在空间连续变化,可分为分布参数模型和集中参数模型;根据模型参数是否随时间连续变化,可分为连续系统模型和离散系统模型;根据模型的数学描述形式,又可分为常微分方程、偏微分方程、差分方程、离散事件模型等。
对于上述不同类型的模型,这里只讨论建立系统数学模型中的几个共性问题。
(1)建模的过程是一个信息处理的过程,换而言之,信息是构造模型的“原材料”,根据建模所用的不同类型“原材料”可将建模方法归为两类:一类是演绎法建模,即利用先验的技术信息建模。其过程是:从某些前提、假设、原理和规则出发,通过数学逻辑推导来建立模型。因此,这是一个从一般到特殊的过程,即根据普遍的技术原理推导出被仿真对象的特殊描述。另一类是归纳法建模,即利用对真实系统的试验数据信息建模。其过程是:通过对真实系统的测试获得数据,这些数据中包含着能反映真实系统本质的信息,然后通过数据处理的方法,从中得出对真实系统规律性的描述,例如大家熟知的最小二乘回归模型等。这是一个从特殊到一般的过程。
但是实际应用中,常常是通过上述两类方法的结合完成模型的建立,即混合法建模。不管用哪种方法建模,其关键都在于真实系统的了解程度。如果对真实系统没有充分的和正确的了解,那么所建的模型将不能准确地模仿出真实系统的本质。
(2)模型的可信度。既然模型是对真实系统的模仿,那么就有一个模仿得像不像的问题,这就是模型的相似度、精度的可信度的问题。模型的可信度取决于建模所用的信息“原材料”(先验知识、试验数据)是否正确完备,还取决于所用建模方法(演绎、归纳)是否合理、严密。此外,对于许多仿真 软件来说,还要将数学模型转化为仿真算法所能处理的仿真模型。因此,这里还有一个模型的转换精度问题。建模中任何一个环节的失误,都会影响模型的可信度。
为此,在模型建立好以后,对模型进行可信度检验是不可缺少的重要步骤。检验模型可信度的方法通常是:首先由熟悉被仿真系统的专家对模型作分析评估,然后对建模所用数据进行统计分析,最后对模型进行试运行,将初步仿真结果与估计结果相比较。
2.仿真计算
仿真计算是对所建立的仿真模型进行数值实验和求解的过程,不同的模型有不同的求解方法。例如:对于连续系统,通常用常微分方程、传递函数,甚至偏微分方程对 其进行描述。由于要得到这些方程的解析解几乎是不可能的,所以总是采用数值解法,如:对于常微分方程主要采用各种数值积分法,对于偏微分方程则采用有限差 分法、特征法、蒙特卡罗法或有限元方法等。
又例如:对于离散事件系统,通常采用概率模型,其仿真过程实际上是一个数值实验的过程,而这些参数又必须符合一定的概率分布规律。对于不同类型的离散事件系统(如随机服务系统、随机库存系统、随机网络计划等)有不同的仿真方法。
随着被仿真对象复杂程度的提高和对仿真实时性的迫切要求,研究新的仿真算法一直是一项重要的任务,特别是研究各种并行的仿真算法。
3.仿真结果的分析
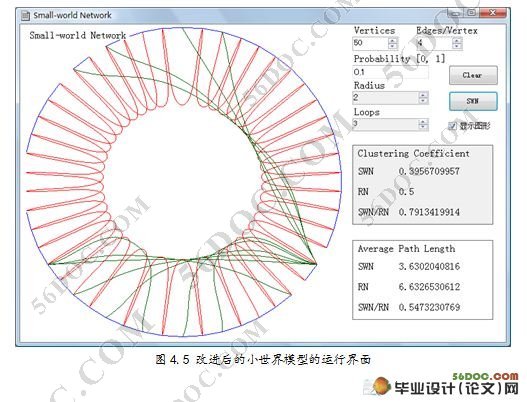
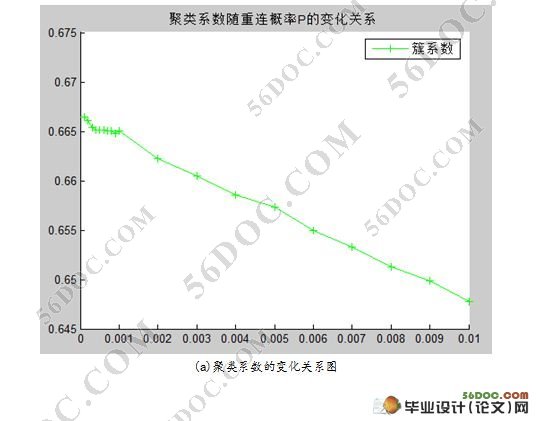
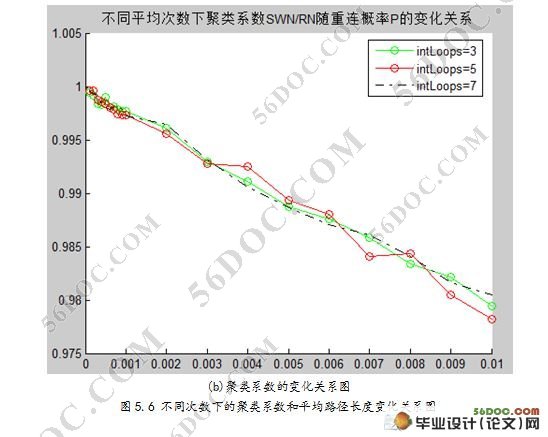
要想通过模拟仿真得出正确、有效地结论,必须对仿真结果进行科学的分析。早期的仿真软件都是以大量数据的形式输出仿真的结果,因此有必要对仿真结果数据进行 整理,进行各种统计分析,以得到科学的结论。现代仿真软件广泛采用了可视化技术,通过图形、图表,甚至动画生动逼真地显示出被仿真对象的各种状态,使模拟 仿真的输出信息更加丰富、更加详尽、更加有利于对仿真结果的科学分析。
(2)开发本课题所使用的语言
CSharp是微软公司发布的一种面向对象的、运行于.NET Framework之上的高级程序设计语言。并定于在微软职业开发者论坛(PDC)上登台亮相。CSharp是微软公司研究员Anders Hejlsberg的最新成果。CSharp看起来与Java有着惊人的相似;它包括了诸如单一继承、接口、与Java几乎同样的语法和编译成中间代码再运行的过程。但是CSharp与Java有着明显的不同,它借鉴了Delphi的一个特点,与COM(组件对象模型)是直接集成的,而且它是微软公司.NET windows网络框架的主角。并且CSharp成为ECMA与ISO标准规范。CSharp看似基于C++写成,但又融入其它语言如Delphi、Java、VB等。
论文的章节安排
本论文的文章安排如下:
第2章介绍人肉搜索;
第3章介绍复杂网络理论及小世界网络模型;
第4章则介绍小世界网络模型和本课题研究模型的建立;
第5章对数据进行分析。
最后:结论、致谢、参考文献。
|