ЙиСЊЙцдђЭкОђдкЪ§зжЭМЪщЙнЕФгІгУ
РДдДЃК56doc.com зЪСЯБрКХЃК5D9183 зЪСЯЕШМЖЃКЁяЁяЁяЁяЁя %E8%B5%84%E6%96%99%E7%BC%96%E5%8F%B7%EF%BC%9A5D9183
зЪСЯвдЭјвГНщЩмЕФЮЊзМ,ЯТдиКѓВЛЛсгаЫЎгЁ.зЪСЯНіЙЉбЇЯАВЮПМжЎгУ. Ум БЃ Лн Аяжњ
зЪСЯНщЩм
ЙиСЊЙцдђЭкОђдкЪ§зжЭМЪщЙнЕФгІгУ(КЌбЁЬтЩѓХњБэ,ШЮЮёЪщ,ПЊЬтБЈИц,БЯвЕТлЮФЫЕУїЪщ10000зж)
еЊ вЊЃКИпаЃЭМЪщЙнзїЮЊИпаЃЪІЩњЕФвЛИіживЊжЊЪЖПтЃЌЙнФкВиЪщЫљЩцМАЕФСьгђЗЧГЃЙуЗКЃЛЭМЪщЙнУПФъЙКШыаТЪщЃЌвђДЫЭМЪщЙнВиЪщСПвВдкВЛЖЯдіЖрЁЃЪІЩњУЧвЊдкжкЖрЕФЪщМЎжаевЕНздМКашвЊЕФЯрЙиЭМЪщЪЧвЛМўЗЧГЃРЇФбЕФЪТЧщЁЃвђДЫЃЌПьЫйгааЇЕФгХЛЏВиЪщВМОжЖдЪІЩњЕФбЇЯАгыбаОПЯдЕУгШЮЊживЊЁЃБОПЮЬтЕФФПБъОЭЪЧдЫгУЪ§ОнЭкОђжаЕФЙиСЊЙцдђЗНЗЈЃЌДгЖСепЕФРњЪЗНшдФЪ§ОнжаПьЫйгааЇЕиЭкОђГіНшдФЪщМЎжЎМфЕФЙиСЊаХЯЂЃЌРДАяжњЙмРэдБгХЛЏВиЪщВМОжЁЃ
гЩгкЭМЪщЙнНшдФЪ§ОнУПШегаИќаТЃЌЪ§ОнПтВЛЖЯдіДѓЃЌВЂЧвИљОнашвЊЕФЙиСЊГЬађЖШВЛЭЌЃЌзюаЁжЇГжЖШвВгаБфЛЏЁЃЮЊСЫЪЙЭМЪщАкЗХФмЙЛОЁПьЪЪгІЪІЩњНщгкашЧѓЃЌашвЊВЛЖЯЕиИќаТЭкОђНсЙћЁЃЮЊДЫЃЌБОЮФЬсГідЫгУMFIA-IUЫуЗЈРДНтОіЪ§ОнПтКЭзюаЁжЇГжЖШЭЌЪББфЛЏЪБЕФзлКЯИќаТЭкОђзюДѓЦЕЗБЯюФПМЏЕФЮЪЬтЃЌДгЖјПЩБмУтУПФъЖдОЩЪ§ОнЕФжиИДЭкОђЁЃ
ЙиМќДЪЃКЪ§ОнЭкОђЃЛЙиСЊЙцдђЃЛзюДѓЦЕЗБЯюФПМЏЃЛ Apriori
Application of Association Rules Mining in Digital Library
AbstractЃКAs an important knowledge base for teacher and students, university libraries cover a very wide field of books. Books are bought annually, so the number of books increases constantly. It is not pleasant for teacher and students to find books relevant to their own needs, so optimizing the layout of books quickly and effectively becomes more and more important for teacher and students. The dissertation is to mine the association information among the borrowed books from the history data quickly and effectively with association rules methods data mining.
Due to the data of borrowed books is updated daily, the database becomes bigger continuously, and as the need of association degree is different, the minimal support is changed sometimes. In order to meet the need of teachers and students to borrow books as convenient as possible, it is necessary to update the mined results constantly. So the MFIA-IU algorithm is proposed to mine comprehensive updated maximum frequent sets when the database and the minimal support change simultaneously. thereby, the annually repeated mining of the old data is avoided.
Key wordsЃКData mining; Association rule; Maximum frequent sets; Apriori
баОПЗНАИ
баОПФПЕФЃКдЫгУЪ§ОнЭкОђжаЕФЙиСЊЙцдђЗНЗЈЃЌДгЖСепЕФРњЪЗНшдФЪ§ОнжаПьЫйгааЇЕиЭкОђГіНшдФЪщМЎжЎМфЕФЙиСЊаХЯЂЃЌРДАяжњЙмРэдБгХЛЏВиЪщВМОжЁЃ
баОПФкШнЃКдЫгУЪ§ОнЭкОђжаЕФЙиСЊЙцдђЗНЗЈЃЌДгЖСепЕФРњЪЗНшдФЪ§ОнжаПьЫйгааЇЕиЭкОђГіНшдФЪщМЎжЎМфЕФЙиСЊаХЯЂЁЃ
баОПЗНЗЈЃКдЫгУЙиСЊЙцдђЕФЗНЗЈЁЃАќРЈЪ§ОнЕФЪеМЏЃЌЪ§ОнЕФГ§“ды”ЕШдЄДІРэЃЌРћгУAprioriЫуЗЈНјааЭкОђЃЌзюКѓЕУГіНсТлЁЃ
дЄЦкНсЙћЃКПЩвдИљОнЫљеЦЮеЕФЪ§ОнЕУГіНтгєЭшЪщМЎжЎМфЕФЙиСЊаХЯЂЃЌЗНБуЙмРэдБгХЛЏВМОжЁЃ
ЬѕМўБЃеЯЃКЪ§ОнецЪЕгааЇЁЃ
ећИіжЊЪЖЭкОђЕФжївЊВНжшгаЃК
ЃЈ1ЃЉЪ§ОнЧхЯДЃЌЦ№зїгУОЭЪЧЧхГ§Ъ§ОндыЩљКЭгыЭкОђжїЬтУїЯдЮоЙиЕФЪ§ОнЁЃ
ЃЈ2ЃЉЪ§ОнМЏГЩЃЌЦфзїгУОЭЪЧНЋРДздЖрЪ§ОндДжаЕФЯрЙиЪ§ОнзщКЯЕНвЛЦ№ЁЃ
ЃЈ3ЃЉЪ§ОнзЊЛЛЃЌЦфзїгУОЭЪЧНЋЪ§ОнзЊЛЛЮЊвзгкНјааЪ§ОнЭкОђЕФЪ§ОнДцДЂаЮЪНЁЃ
ЃЈ4ЃЉЪ§ОнЭкОђЃЌЫћЪЧжЊЪЖЭкОђЕФвЛИіЛљБОВНжшЃЌЦфзїгУОЭЪЧРћгУжЧФмЗНЗЈЭкОђЪ§ОнФЃЪНЛђЙцТЩжЊЪЖЁЃ
ЃЈ5ЃЉФЃЪНЦРЙРЃЌЦфзїгУОЭЪЧИљОнвЛЖЈЦРЙРБъзМДгЭкОђНсЙћЩИбЁГігавтвхЕФФЃЪНжЊЪЖЁЃ
ЃЈ6ЃЉжЊЪЖБэЪОЃЌЦфзїгУОЭЪЧРћгУПЩЪгЛЏКЭжЊЪЖБэДяММЪѕЃЌЯђгУЛЇеЙЪОЫљЭкОђГіЕФЯрЙижЊЪЖЁЃ

ФП ТМ
еЊ вЊ 1
ЙиМќДЪ 1
1 ЧАбд 2
2 Ъ§ОнЭкОђИХЪі 2
3 ЙиСЊЙцдђ 3
3.1 ЙиСЊЙцдђЛљБОРэТл 3
3.2 ЙиСЊЙцдђжаЕФЛљБОИХФю 3
3.2.1 ЯюгыЯюМЏ 3
3.2.2 ЪТЮё 3
3.2.3 ЯюМЏЕФЦЕТЪ 4
3.2.4 ЙиСЊЙцдђ 4
3.2.5 ЯюМЏЕФжЇГжЖШКЭжУаХЖШ 4
3.2.6 зюаЁжЇГжЖШгызюаЁжУаХЖШ 4
3.2.7 ЦЕЗБЯюФПМЏ 4
3.2.8 ЯрЙиЗжЮі 4
3.2.9 ЧПЙцдђ 5
3.3 ЙиСЊЙцдђЭкОђЕФГЃгУЫуЗЈ 5
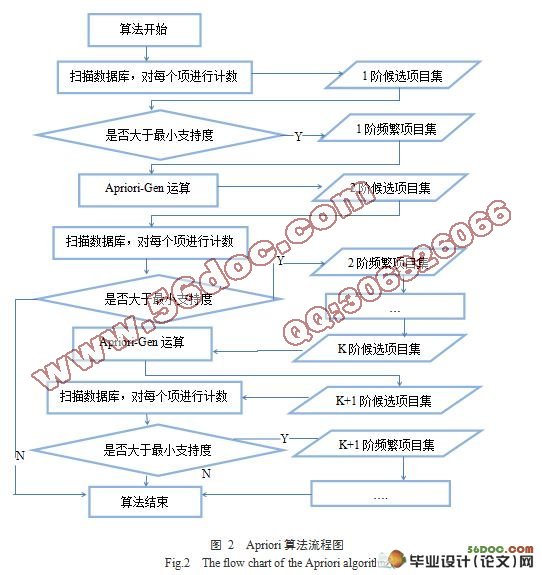
3.3.1 AprioriЫуЗЈ 5
3.4 AprioriЫуЗЈЕФCгябдЪЕЯж 7
3.5 ЙиСЊЙцдђЭкОђдкЙњФкЭтЕФгІгУ 10
4 ЙиСЊЙцдђЭкОђдкЭМЪщЙнЕФгІгУ 11
4.1 Ъ§ОнбЁШЁ 12
4.2 ЭМЪщЙнНшдФЪ§ОнЕФдЄДІРэ 13
4.3 ЙиСЊЙцдђЭкОђЕФЙ§ГЬ 15
4.4 ЙиСЊЙцдђЭкОђНсЙћ 17
5 НсТл 17
ВЮПМЮФЯз 17
жТ аЛ 19
|
